On the 29th June 2026 - if you searched for Jim Carrey on Google, you would have been presented with a Knowledge Panel stating that he had died the previous day. The panel included a date of death and a biography written in the past tense.
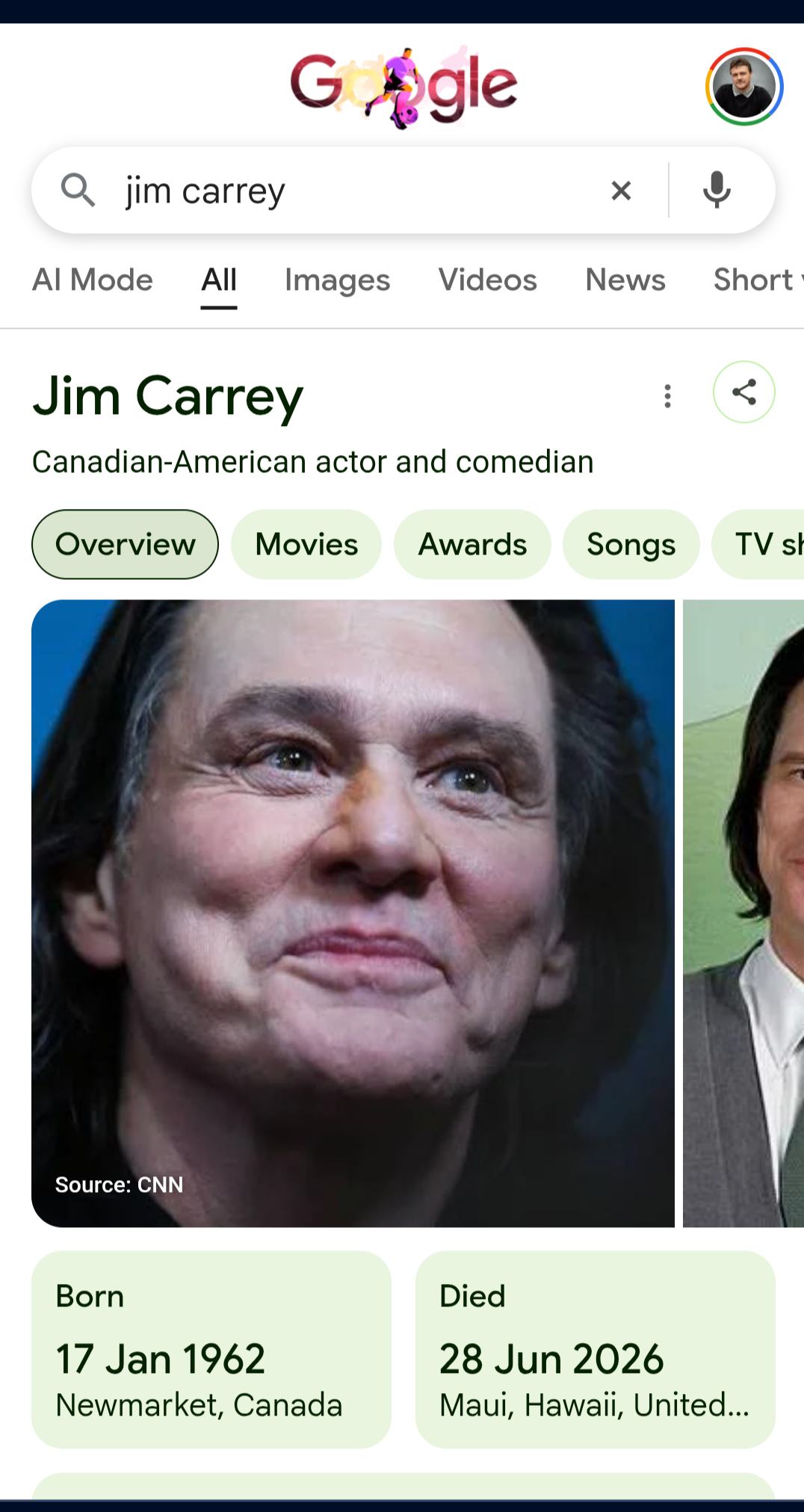

For most people who would have seen this, it may have come as a shock - some may have even believed it - but for me, what I saw was a canary in the coal mine. It was a visible failure mode of a knowledge system that I have been thinking about for a while now.
A trusted source?
Clicking on the date of death brings up Google’s own AI - Gemini - which stated that reports of his death were false. This led me to do a bit of my own digging around, and I could only find one source - an edit on the Wikipedia page that cited the Maui Police Department’s Facebook page and an established BBC article about former US President Jimmy Carter’s death.
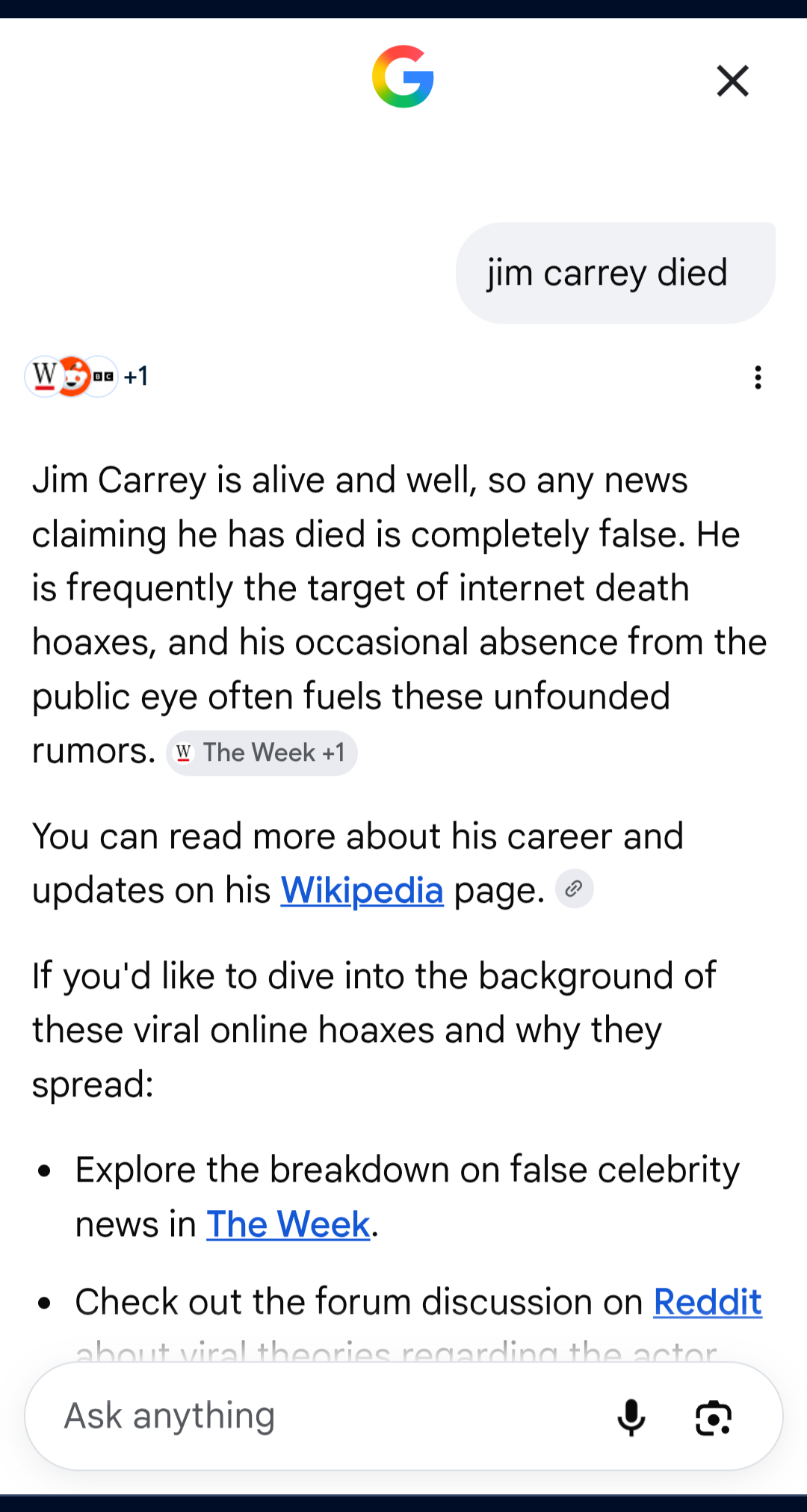

It would seem this is an open-and-shut case: Wikipedia was edited, Google consumed the edit, their Knowledge Graph updated and presented this as a fact - but now we have two conflicting reports from the same company - one saying he is dead, and the other saying he is alive.
I don’t know exactly where the false claim entered Google’s systems and whether the Wikipedia edit was involved. All we can infer is that a combination of source weighting, entity resolution, indexing, freshness signals and internal systems produced the result. From outside the company, there is no way to know that. Google’s own description of the Knowledge Graph has always made clear that it is assembled from multiple public and web-derived sources, structured information and internal interpretation. The panel is the user interface to the knowledge of a much larger, opaque pipeline. Somewhere in that pipeline, a claim crossed a threshold and stopped being information that existed somewhere on the web and became knowledge presented by an interface that many people use and trust to find information.
Building knowledge systems is hard
My day job involves building knowledge systems. That description tends to make people think of the technologies involved: content, knowledge and document management systems, APIs, knowledge graphs, product information, search, integrations, semantic models, and now AI. While those things do matter, the main bulk of my work is less about moving information between systems and more about building systems that people can trust.
Every system that receives information has to make a judgement about it - in biological systems we call this perception, in technological systems we call this inference.
- “Does this agree with what I already know?”
- “Is the source authoritative in this domain?”
- “Has this changed since the last time I saw it?”
- “Does it conflict with something else?”
- “Is the claim sufficiently important, recent or well-supported to pass further downstream?”
By the time a user sees an answer, those decisions have already been made several times by systems they will never see, and algorithms they will never be shown. In the end, all the user sees is a result, but not the process that produced it.
We use the words information and knowledge almost interchangeably, although they describe very different things. Information is a claim about the world. Knowledge is a claim that has survived enough scrutiny that another person, or increasingly another system, is prepared to act on it. The transition between those states is almost entirely invisible: users only see an output or outcome - those decisions have already been made several times by systems they will never see, and algorithms they will never be shown.
They do not see the claims that were discarded, the sources which disagreed, the confidence thresholds, the causal relationships between documents, or the fact that another internal system may have reached a different conclusion. One of the great sins of UX Design is that the interface tends to present the final answer as though it arrived fully formed.
The report of Jim Carrey’s death itself is of low consequence, but it exposed that hidden process for a brief moment - a claim that should have remained an assertion appears to have been promoted before the available evidence confirmed it. Whether that was caused by malicious manipulation, a weakness in source reconciliation, a problem in how to handle fresh data, or some combination of those things is almost secondary. The failure mode exists either way. A knowledge system can inherit confidence from upstream sources faster than it inherits the verification required to deserve that confidence.
The shape of misinformation
Propaganda and misinformation existed long before the internet era, but with opaque systems it’s never been easier and faster to produce them. A false article is published, designed to trigger people’s emotions, people share it, and by the time journalists or fact-checkers catch up, the narrative has already achieved much of its purpose. The old line, usually attributed to Mark Twain even though the attribution itself is uncertain, says that a lie travels halfway around the world while the truth is still putting on its shoes. In the past, you needed to own a media empire to achieve this. Today, all it needs is a social media platform and people to click, share and like. The speed of distribution has increased, but the underlying pattern is the same: a claim can be repeated and amplified faster than it can be verified.
But I believe that now in the ‘Age of AI’ there is a new emergent version that looks less social-technical and more like an infrastructure problem.
A false claim does not need to persuade millions of people individually if it can persuade, or merely pass through, the systems that decide what millions of people see. A carefully shaped claim with plausible references, structured fields, apparent corroboration and the right entity identifiers can become input to the systems that now summarise, rank, recommend and answer on our behalf. The target has moved upstream from users to the machines that mediate people’s relationship with reality.
Software engineering is already grappling with this as supply-chain risk. For a long time, software security was focused on applications - RBAC, access control lists, security patches - but then it became obvious that applications were not the only attractive target, and attacking dependencies is much cheaper and easier to do. Modern software supply-chain practice is built around provenance, attestations, reproducible builds, signatures and the ability to trace an artefact back through the process or pipeline that created it. We have learned that software cannot be trusted simply because it is available in a repository run by large organisations: trust depends on understanding where it came from, who created it, how it was assembled and what metadata has been attached to it along the way. I believe the same is now true of knowledge.
Claims also have origins, dependencies and supply chains - they inherit trust from upstream systems, but they also inherit mistakes, gaps and manipulation. A claim copied across a hundred pages may look like consensus while remaining one upstream observation reflected in a hundred different places. A citation can look like evidence while pointing towards a source that does not support the claim. A polished summary can make uncertainty disappear without resolving it. We’ve fallen into a trap where information has not become more reliable; it merely acquires the appearance of reliability.
That distinction is where provenance becomes more important than confidence. A system saying that it is ninety-four per cent confident is not particularly useful unless it can explain what produced that confidence.
- “Is the source authenticated?”
- “Is it the original source?”
- “Are there genuine independent confirmations?”
- “Has the claim remained stable over time?”
- “Does it contradict other information already held by the system?”
- “Has the underlying observation been repeated?”
Confidence without this context becomes merely presentation - it may make an answer feel truthful, but it does not tell us whether the answer is true.
Prior art of verification
Science has spent centuries developing ways to deal with this problem. When a scientist publishes a paper in a journal - it doesn’t immediately become accepted knowledge. Publication begins a process of scrutiny: other researchers examine methods, challenge assumptions, reproduce calculations and attempt to replicate results. Independent groups of researchers may arrive at the same conclusion through similar or different methods.
Sometimes confidence grows because the evidence survives repeated scrutiny of the original claim. Sometimes, however, confidence collapses, leading to corrections, and occasionally the work is retracted entirely.
Retractions are often presented as embarrassing exceptions, as though science has failed when it admits that something previously published should no longer be trusted. But retractions are evidence that the system remains corrigible - that things can be corrected or set right. Publication is not the end of the scientific process; it’s the start of a process that makes the claim eligible for a stronger kind of scrutiny.
The replication crisis reinforced that lesson across multiple scientific disciplines - it showed that peer review is valuable, but that it’s not always sufficient. Scientific knowledge required additional verification layers because the cost of confusing publication with truth had become too high.
We see this too in historical patterns beyond science - in fact, every major shift in how information and knowledge is distributed eventually requires a corresponding shift in how it is verified.
When written records were scarce, the ability to create and preserve them was concentrated in relatively few institutions. Monasteries, royal courts and university archives became custodians of texts as much as producers of them. Their authority was never a guarantee of truth, but access to durable writing and copying imposed a kind of scarcity that shaped what has survived to this day. The printing press changed that - once texts could be reproduced at scale, publication itself ceased to carry the same authority. We responded slowly by constructing new layers around the printed word: editors, publishers, editions, libraries, citations, journals, review and later peer review.
Newspapers and mass media intensified the problem because they combined reach with speed. The answer could reach a large audience before the underlying event had fully settled. Editorial desks, named sources, corrections, libel law and newsroom standards emerged as ways of creating enough friction that a printed claim could carry some degree of trust. Broadcast media added immediacy and mass scale, bringing regulators, editorial governance and public-service obligations into the picture. This is not a claim that any of these systems are in fact neutral or perfect - they were shaped by power, economics and politics.
But the pattern keeps repeating itself: each increase in distribution capability made existing verification mechanisms insufficient, and new mechanisms had to be invented around the new medium.
The internet has pretty much removed any friction around publishing and distribution - anyone can now have a blog, a YouTube channel or run their own entire platform. Search engines created a new type of verification proxy through ranking, linking and perceived authority - this is how Google won and pushed out the first generation of services like Yahoo! and Ask Jeeves. Social media platforms made distribution algorithmic, measurable and emotionally optimised.
Editorial layers have not disappeared, but they have become a lot easier to bypass. Now AI adds another complication to all of this, because it does not merely distribute or retrieve information - it actively participates in selecting, combining, paraphrasing and promoting information into confident-looking answers.
We can already see that our existing tools for verification completely fail - and I believe this means the verification layer has to move closer to the architecture itself. Systems are no longer only passing along information; they are manipulating the creation of what users experience as knowledge.
Temporal issues
Time is one of the parts of this problem that knowledge systems still model very badly - most knowledge systems assume a static time frame: that when knowledge is created, it’s valid and correct. Reality is messy, though, and claims converge at different speeds, but almost all modern systems assume that every question should have an immediate answer. Indeed, some questions can be resolved almost instantly - while other claims require hours, days, months or even years before they can be validated. A scientific result may remain provisional until it survives replication; an election result may move through states of projected, counted, challenged and certified until a winner is confirmed; and a report of a death may remain unconfirmed until there is a statement from family, representatives or public authorities.
We’ve seen this play out many times in US politics - the famous ‘Dewey Defeats Truman’ headline is an example of the press getting an election wrong (we’ll skip the ideological reasons here for now). The headline turned uncertainty into certainty before the counting was finished. It was premature rather than merely inaccurate. This was repeated again in 2000 - during the Florida recount and the legal processes that followed, the most accurate representation of the situation was that the result remained unresolved. Choosing Bush or Gore too early was not just a choice between two candidates; it was a system that had not yet reached a grounded state. The Supreme Court’s decision in Bush v. Gore brought that process to a conclusion, but for a period, the uncertainty was not a defect in the information: it was the only information.
The 2020 United States election represents an entirely different state. In the end, the outcome was certified and electoral votes were counted. Recounts and legal challenges took place, and the formal system reached a conclusion. Joe Biden received 306 electoral votes to Donald Trump’s 232.
But that did not produce universal belief. Donald Trump continued to claim that the election had been stolen, and many of his supporters accepted that claim despite a rigorous certification process and the absence of evidence sufficient to overturn the result. Public belief remained divided after the institutional process had converged on the result.
These are different epistemic states, and knowledge systems desperately need a language for them. In 2000, uncertainty was the reality - the process had not reached a stable conclusion. In 2020, the evidence had converged and the result was verified, but a portion of the population continued to reject it, and still do to this day. The problem is that without proper semantics, systems may treat both states as “uncertain” without a clear distinction; this can confuse the absence of a settled, verified result with the refusal to accept a result.
Distributed systems already offer a useful way of thinking about this: engineers understand that state is not simply correct or incorrect. In distributed systems, data may be stale, partitioned, inconsistent, awaiting consensus, eventually consistent or in conflict. We do not demand that every replica across the system knows the final state before the system has converged. Knowledge systems increasingly have the same shape, except the object being replicated is not a database row - rather, it is an interpretation of reality.
A claim may be observed in one source, contradicted in another, supported by a third, and still waiting for enough independent evidence to justify promotion. The system needs to represent those states rather than flatten them into a single confident answer without context - it needs to be able to represent the fact that a claim is unresolved, disputed or contradicted, and that it may change over time as new evidence emerges.
Aristotle’s Mistake
This is where the simple true-or-false model begins to look inadequate - we now need to be able to represent ’the law of the excluded middle’.
Claims can be in multiple states at once - asserted, supported, corroborated, unresolved, disputed, promoted, superseded, retracted or rejected. The labels are less important than the ability to distinguish these as separate conditions across systems. A claim that has been widely repeated but traces back to one source should not look like a claim independently corroborated by several sources. A claim that contradicts existing knowledge should not necessarily be discarded, but it should not be promoted as though no contradiction exists. A claim that was reliable last year may be stale today. A claim that was accepted yesterday may need to be retracted tomorrow.
Knowledge needs a lifecycle that can support multiple states, and systems need to be able to represent those states in a way that is understandable, inspectable and auditable. The system should be able to explain why a claim is in a particular state, what evidence supports it, what evidence contradicts it, and what the process would be for changing its state.
The Referee is Blind
The World Cup provides an unexpectedly useful example of how this might work in practice.
VAR (Video assistant referee) was not introduced because referees were incapable of making decisions: football accepted imperfect results for more than a century. VAR appeared because certain decisions carry enough consequence that additional evidence and review are justified.
Crucially, it does not review every pass, every foul or every throw-in: it is restricted to match-changing decisions: goals, penalties, direct red cards and cases of mistaken identity. The protocol is designed around correcting clear and obvious errors or serious missed incidents, while attempting to maintain the ordinary flow of the match. VAR also demonstrates something that is easy to overlook - better verification does not produce universal agreement. Supporters will still argue about decisions; managers will still complain. An entire stadium can watch the same evidence and remain convinced that the outcome was wrong.
The purpose of the system was never to make everyone believe the decision. It was to create a more justified, inspectable and consistent process for reaching it.
That is a useful design principle for knowledge systems. Verification should be proportional to consequence. A celebrity biography can tolerate a weaker promotion path than emergency guidance. A product description can tolerate more uncertainty than a medical recommendation. A breaking-election projection should not be presented in the same way as a certified result. Low-risk claims move quickly with lighter verification; a high-risk claim should face stronger provenance requirements, independent corroboration, contradiction checks, temporal stability and perhaps bring a human into the loop.
That distinction carries over directly into many areas of reality. Science does not eliminate disagreement (Only 68% of physicists believe the Big Bang started as a hot, dense state), Courts do not eliminate disagreement , Election systems do not eliminate disagreement.
Verification is not a process for manufacturing belief; rather, it is a rigorous process for increasing justified confidence, preserving the possibility of challenge and making it possible to understand how a conclusion was reached. Knowledge systems should optimise for that, rather than treating universal acceptance as the goal.
Engineering Philosophy
This points towards a practical architecture for knowledge stewardship. It does not need to be a rigid global truth machine: different domains will require different thresholds, sources and review processes as the risk profile increases, but it does need to preserve a few things that current systems often discard too early.
A claim should enter the system with its provenance intact: source, timestamp, original context, transformations, identifiers, and relationship to any upstream assertions. Systems should know whether support is independent or derivative, because repetition cannot be allowed to masquerade as corroboration. They should distinguish corroboration from replication, since some domains require confirmation that an underlying observation or method can be reproduced, rather than merely quoted. They should model temporal behaviour, allowing claims to remain unresolved where reality has not yet converged and allowing old claims to decay, be reviewed or be downgraded when their supporting evidence becomes stale.
Contradiction should become a first-class state rather than an exception - the delta between two competing claims is itself information, and could signal a need to update knowledge. A report that conflicts with recent verified activity, official records or another high-trust source should trigger review, lower the confidence of the claim, or prevent promotion until the contradiction can be explained. In a mature system, contradiction is useful information. It tells the system that the world may be changing, that sources may be wrong, that entities may have been confused, or that the claim has simply not yet earned any of the authority it is attempting to acquire.
Promotion of knowledge itself should be observable. Software does not move directly from someone writing code to production without a lifecycle. It is built, tested, reviewed, deployed, monitored, rolled back and eventually retired.
Knowledge should have comparable states. A claim may be asserted, then sourced, then supported, then corroborated, then promoted for use in an answer. Later it may be challenged, superseded or retracted. A correction should travel downstream with at least as much seriousness as the original claim. Systems that can publish but cannot meaningfully withdraw or correct are dangerously one-directional: they are good at creating confidence but make no attempt to repair it.
This has implications for AI systems in particular. A language model can preserve the words of an uncertain source while completely removing the uncertainty that gave those words their proper meaning. It can take caveats, conflicting evidence and incomplete reporting, then compress them into a fluent paragraph that sounds correct. The underlying uncertainty has not been resolved; rather, the summarisation just removes it. A trustworthy system needs to carry epistemic state through retrieval, ranking and generation.
If the source is uncertain, the answer should remain uncertain. If evidence is disputed, the dispute should be part of the summary. If the claim is newly observed and not yet corroborated, the interface should not present it with the confidence that it is a settled fact.
Governance requires that someone decide which sources are authoritative for which kinds of claim, but these decisions must always remain domain-specific. In any domain, facts require independent corroboration, and until recently we’ve made human review mandatory. We need to enforce how long a claim remains valid before it needs to be reconsidered, and how any corrections must propagate across systems.
These decisions tend already to exist outside of software and data systems; those that are built for this are encoded in business rules - but when systems are not designed for this from the outset, the risk is that these decisions will emerge from ranking algorithms, caching behaviour, data contracts, product incentives and organisational convenience as a sort of ‘governance-by-accident’.
The truth will not be free
A few years ago I said that truth might eventually become like bottled water: clean information will be packaged and sold to those who can afford it; everyone else will need to get what they can from the dirty tap.
This doesn’t mean that truth will become scarce; however, it may become a privilege: information that has been filtered, checked, corrected and made safe enough to rely upon. Everyone else will still have access to truth, of course, but it may arrive mixed with rumour, repetition, manipulation, stale facts and deliberate contamination. The ‘dirty tap’ will not contain only lies, and that is what makes it dangerous: it will contain enough truth to make the rest difficult to detect.
Knowledge may be heading in the same direction. The valuable systems will not be those with the most information or the smoothest prose. They will be the systems that can show where a claim came from, how it was promoted, what supports it, what contradicts it, whether the evidence has converged and how the system would correct itself if it turns out to be wrong. The scarce resource will be the ability to demonstrate that the information has been stewarded rather than merely propagated.
The report of Jim Carrey’s death was harmless by comparison with the kinds of failure this could produce elsewhere. It was a celebrity death hoax - visible long enough to be odd and then easy enough to dismiss - but failure modes often introduce themselves that way. They appear first as mildly absurd incidents which reveal the shape of a deeper weakness before someone finds a way to exploit it at a scale that causes actual harm.
The same pattern becomes far more serious when it touches emergency information, medical guidance, public safety, legal rights, product safety, financial markets or democratic institutions. The systems mediating those decisions will face the same underlying challenge: deciding when a claim has earned the right to be presented as knowledge, and doing so in a way that preserves provenance, uncertainty, correction and accountability.
For most of human history, the question “How do we know?”—often without a clear answer—belonged to philosophy. Over the last few centuries, it became one of the central questions of science. The systems now being built place that question directly inside software architecture. The next decade will spend less time discovering how quickly information can move and more time learning how information earns the right to be trusted.